

Full Stack Development: Sleep Data Web App
Environment
Python 3.7 with: Dash, Plotly, Dash Bootstrap Components, Pandas, Matplotlib, Numpy, Statsmodels, Itertools, Datetime, JSON, pytz, os, RE, Requests, Selenium, Seleniumwire, Brotli
A conda environment for the web app was created, and all of the programming was implemented in python scripts. All of the associated files have been placed in my project repository on Github, and the README.md file provides instructions for how to use the scripts and deploy the web app to Heroku or locally on a Windows machine.
Introduction
For my whole adult life I have been a night owl, rarely falling asleep before 1AM. One of the appeals to wearing a smartwatch has been the potential to quantify my unusual sleep patterns. But smartwatch manufacturers provide limited tools to visualize the data. A few of my lurking questions were:
- How does my sleep vary within a year?
- How do daylight savings time changes and the time of sunset effect my sleep?
- How does my sleep vary year-to-year?
My goal for this project was to produce a public web app which provides visualizations to answer these questions. Making it publicly available would make easy to share as part of my portfolio and it would give me experience deploying my work to a web server. Lastly, I wanted the app to be able to automatically get new data from Garmin so I could continue monitoring my sleep without constant deployment updates. This project represents a full stack solution because it encompasses everything from web scraping to app deployment. A screenshot of the finished dashboard is provided below.
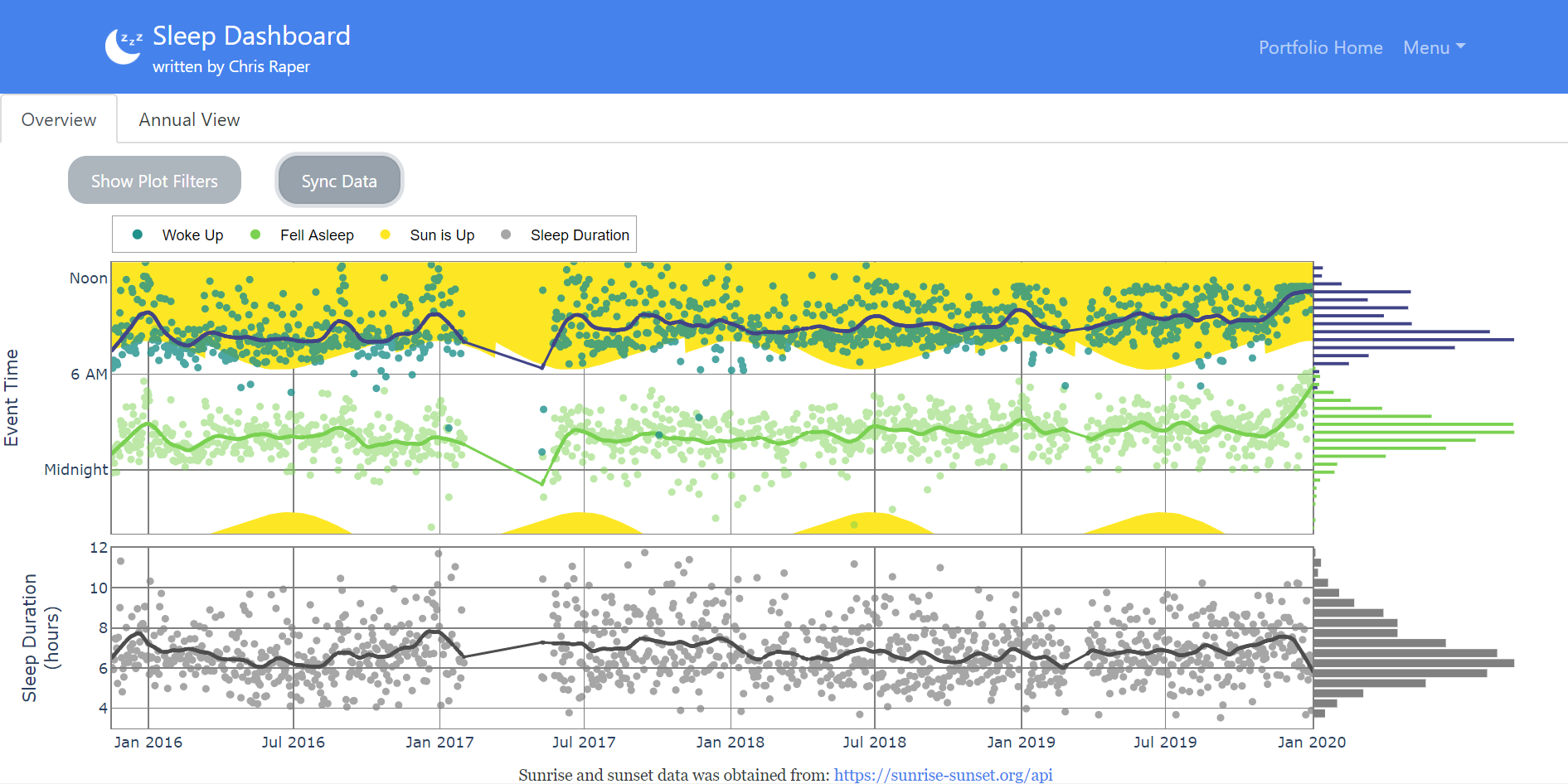
Comparing years against one another, there doesn’t seem to be a repeating pattern, except around Christmas, because I’m always off work for at least 7 days. Daylight savings time changes appear to have negligible effects. Lastly, there is a surprising amount of variation year-to-year.
Discussion
Data
The data used for this app begins with my Microsoft Health band (worn from 2015 to 2017). I had previously downloaded all of this data through a third party website as CSV files. The app also uses all of my Garmin data (worn from 2017 to now). I used my last portfolio project to accomplish the tasks of scraping my Garmin data, wrangling it into a usable format and merging it with my Microsoft data. This provides sleep data for more than 1,200 nights.
Dashboard Features
The dashboard provides two views of the data via tabs underneath the blue navigation bar. The first view is an overview, which shows the whole time-series since data was first collected in 2015. The second tab view shows the data on an annual basis, allowing years to be compared against each other. Along the y-axis the graphs show the time of day when I fell asleep, woke up time, the sun rose and set. The graphs also show the duration of my sleep for each date. The graphs also provide smoothed local regression (Lowess) trend line for these variables. These graphs can also be filtered for various types of days (e.g. days of week, work day, off day).
Dashboard Development
Ultimately, ~1,900 lines of Python were written (including comments and whitespace) to produce this dashboard. It was developed using the packages plotly|Dash and Dash Bootstrap Components. Dash enables developers to deploy plotly interactive figures to a server as a Flask app. Dash Bootstrap Components extends Dash’s html capabilities with the very popular html Bootstrap framework, which is designed to, “build responsive, mobile-first projects on the web.” Dash Bootstrap Components also supports 20 Bootswatch CSS themes to produce different website styles.
Dashboard Deployment
Lastly, the dashboard was deployed on the Heroku platform, which provides hosting services spanning from free personal accounts to enterprise accounts. Deployment is accomplished by a command line tool which enables Git repositories to be pushed to Heroku. A custom environment is then built and the web service is launched. All of the tools above enabled a public web-based dashboard to be deployed using nothing but Python and git.
Challenges
The following list is meant to highlight the various challenges I encountered in this project as well as to share some of my solutions.
- Improving my web-scraping code so that data which had already been downloaded wouldn’t be downloaded again. Without this, each update would take more than 10 minutes to scrape all of the Garmin and sunset/sunrise data.
- Extensive date & time manipulations were needed so that the proper date was referenced for each night of sleep and the time of day was properly represented based on timezone and daylight savings. In conjunction with the datetime package, this effort demonstrated Panda’s powerful date & time capabilities using the
.dtaccessor. - Merging old Microsoft CSV data with Garmin in a consistent manner. In addition to addressing the same date & time concerns as with the Garmin data, this also required identifying and filtering out naps, since Microsoft captured these but Garmin did not.
- Downloading sunrise and sunset times for each date in the dataset based on Indianapolis’ latitude and longitude from the API at https://sunrise-sunset.org/api. This required forming the proper html request and wrangling the json response with more date & time manipulations.
- The desired interactive plots ultimately required ~650 lines of Python code. While I had some previous experience with plotly in R, this was still a big undertaking. This required understanding how subplots are combined, defining custom hover info for data points, defining shaded areas of a plot and transforming data so that smoothed data trends could be plotted.
- The Dash html layout and callback structures ultimately also required ~650 lines of Python code. These packages (Dash and Dash Bootstrap Components) were totally new to me. It was difficult to construe how callback functions should be arranged because an Dash app element can only be updated via a single callback function. For example, this meant that all aspects of a plot had to be updated within a single callback, taking all possible triggers at once.
- Incorporating the data sync capability into the dashbaord was desired because it would be burdensome to manually get new data and push a new version of the dashbard to Heroku. Since the update process is slow, a simple log of the progress was desired. This presented similar technical challenges as when updating a plot, since the log window couldn’t be modified by multiple callbacks and it couldn’t be modified in the middle of a callback. Therefore, several html elements were introduced inside the window, one for each process step. Also the update script was broken into step functions so that the completion of each step could update the log. Lastly, in order to indicate the overall progress, a progress bar was added. Since the bar cannot be modified by each step’s callback, a polling callback was introduced, which polls the step elements every second to derive the overall progress.
- Deploying this app to Heroku also entailed several challenges since I had never attempted a similar deployment before. Firstly, many attempts to deploy the app produced failed builds. Local development was done in conda on Windows, but the deployed build uses pip on Linux. Several build packs were tried to utilize a conda environment definition, but this was unsuccessful because it produced environments (AKA slugs) that were ~1GB in size. Heroku limits slug size to 500MB. It turned out that the earlier failed builds using pip +
requirements.txtwas failing because the package versions from the local conda environment were incompatible in the Linux + pip system. By deleting the version definition of all packages fromrequirements.txt, the app successfully built.
Other deployment issues included modifying the Python code in order run in a server environment. This was discovered with the help of the plotly|Dash community forum here. Also, getting Selenium to run on Heroku involved special build packs and a few additional modifications to my Python code.
What Could Be Improved?
Selenium runs with rare issues in my local conda environment, but it is finicky when running on Heroku. It frequently fails, with various causes. The only reason Selenium is needed is to get a valid session header to append with the json data request. Unfortunately, there doesn’t seem to be a work around to this.
Heroku works by creating ephemeral copies of the deployed application for each user browsing session. Since all of the data is stored within this environment, any updates to the data are lost once the user session ends. To avoid loss of data, it should be stored in a separate cloud location that supports updating.
The app supports filtering “off days”, which are meant to represent nights where I didn’t have work on the following morning. This includes weekends, holidays and PTO. Without access to my previous employer’s records, I don’t have an easy method for getting all of my PTO dates. This could be improved with research in my email and Facebook accounts. For now, many actual PTO days are assumed to be working days.